機械学習に基づく翻訳手法の研究
− 翻訳機「工場」を目指して −
1.はじめに
ATRは翻訳機「工場」を作ろうと考えています。
まず、翻訳機の現状を振り返ってみましょう。翻訳機は、パソコン用のプログラムやWEB上のサービスという形で広く使われています。これらは大きな辞書を備えた一般性を重視した構成をとっていて、幅広い文章を翻訳できますが、反面、その翻訳品質はそれなりです[1]。一方で、世の中は、(1)より高品質な翻訳を、(2)別の分野や言語ペアの翻訳を、さらに、(3)従来の翻訳機の対象外であった話し言葉の翻訳をも求めています。
翻訳機の作り方に視点を移しましょう。従来の翻訳機は、辞書や文法や翻訳規則などの大規模な翻訳知識から構成される複雑なシステムでした。この翻訳知識の作成・維持は高度な作業であり、翻訳対象の両言語に堪能な熟練した専門家以外には出できませんでした。翻訳機の作成は言わば職人芸で、多くの専門家と年単位の時間と莫大な費用を必要としました。
ですから、上記の(1)から(3)の要請に応えるには、まず、翻訳機の新たな作成方法を編み出さなくてはなりません。それは時間も費用もかからない効率的な方法でなければなりません。言い換えれば、できるだけ人の関与をなくして、機械化する。言わば、「翻訳機を生産する工場」を作る必要があります。
2.コーパスベース翻訳
「翻訳機を生産する工場」、そんなものができるのでしょうか? ここで発想の転換のために、19世紀のドイツ人ハインリッヒ・シュリーマン[2]について見てみましょう。彼はトロイの遺跡の発掘だけでなく、語学の達人としても有名でした。彼の勉強方法は普通の方法と著しく違っています。(A)彼は文法に一切時間をかけませんでした。(B)彼は単純に外国語の教科書を丸暗記したのです。この方法で半年に1言語のハイペースで10数カ国語を流暢に話せるようになったそうです。
ここにヒントがあります。普通の人間は丸暗記する暇もないし、記憶の定着性も高くありません。しかし、丸暗記はパソコンの最も得意とするところです。
現在、ATRを始め世界の研究者が盛んに研究している翻訳機の工場は、原材料として手本となる対訳(コーパスと呼びます)を使い、製品である翻訳機を生み出します(図1)。
この方法をコーパスベース翻訳と呼びます。パターン認識などで成功した機械学習の方法を翻訳データに適用するために様々な工夫をしています。コーパスベース翻訳には、用例翻訳と統計翻訳という二つの流儀[3]があります。 ATRでは、この二つを同時に追求し、互いに切磋琢磨しながら研究を進めています[4,5,6]。本稿では、そのうちのD3(Dp-match Driven TransDucer)と呼んでいる研究について詳しくご説明します。D3は単純ですが、高性能です。
3.用例翻訳D3
(1)処理のあらまし
D3では手本となる対訳を大量に丸暗記し、これを直接使って翻訳します。類似対訳を検索し、入力と類似対訳とのズレを対訳辞書を使って調整します。
日英翻訳の例を使って説明しましょう。
下の(1-j)が入力文で、(2-j)と(2-e)の対がお手本の類似対訳で、最後に(1-e)が出力文です。
(1-j)いろ/が/気/に/入り/ません
(2-j)デザイン/が/気/に/入り/ません
(2-e)I do not like the design.
(1-e)I do not like the color.
まず、対訳の全体から、入力文(1-j)に良く似た対訳(2-j)を検索します。違うのは網掛け部分だけなので良く似ています。この検索には、意味を考慮した単語列編集距離を使います。編集距離は長さの異なる列を比較するときに良く使われます。2つの列を一致させるのに必要な編集操作の回数を数えるものです。数式1に従って、単語の挿入 (I)、削除 (D)、置換の各操作の合計回数を入力文と対訳の(入力言語側)の長さの和で正規化します。置換の操作に関しては置換される2単語の意味的な距離(SEMDIST)を考慮します。単語の意味的な距離はシソーラス(単語を意味的な階層関係で整理した辞書)を使い計算します。同じ意味の単語間の距離は0で、意味が似ていない単語間の距離は大きくなります。
数式 1
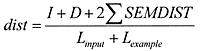
検索された類似対訳の出力側(2-e)について、網掛け部分の単語「design」を、対訳辞書を参照して、「いろ」の対訳「color」に置き換えて、(1-e)が得られます。
(2) 性能
この簡単な手法が、どの程度の性能が出せるか、その性能で役に立つのか等を調べるために、ATRで作成した20万件の大規模な日英対訳データを用いて実験をしました。
翻訳速度は充分高速で、一文当たりの処理時間としては平均0.04秒でした。
翻訳品質も高く、TOEICスコア750点の日本人と同等の翻訳能力を達成しました(音声翻訳能力を測るためにATRが提案した評価手法を用いて、D3のTOEICスコアを求めました。評価手法の詳細は文献[7]をご覧ください)。この750点は、海外部門のビジネスマンの平均点に相当すると言われています[8]。この意味では実用的なレベルに達していると言えるでしょう。
4.おわりに
本稿では、翻訳機の新しい作成方法をご紹介しました。基本的には、大量の翻訳データを記憶し、これに基づいて翻訳する手法です。
これは、1997年に、コンピュータがチェスの世界チャンピオンのカスパロフを破ったことを思い出させます[9]。規則を重視した人工知能のそれまでの手法が果たせなかった夢を、過去の対局を記憶して、その検索に基づいて、次の一手を決めていくという記憶に基づく手法が実現したということは、人工知能研究史に残る大事件でした。翻訳技術においても同様のことが起こりつつあるわけです。
ここでご紹介した方法がすべての面において優れているわけではありません。他の方法がある面では勝っていることも分かっています。ATRは、複数の翻訳機を同時に動かし得られた訳文集合から、訳質自動評価法を用いて最良のものを選択する方法を検討し、有効性を確認しつつあります[10,11]。
新たな課題もあり、前途洋々とはいきませんが、コーパスベース翻訳が翻訳技術の壁に突破口を開いたようです。遠からず、『custom-madeの翻訳機の注文を受けてATR工場の営業が始められるのでは』と隅田@ノウテンキは考え始めたところです。
Copyright(c)2002(株)国際電気通信基礎技術研究所


