
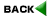


音声スペクトログラム上
音響特徴を用いた音声認識
ATR視聴覚機構研究所 聴覚研究室 片桐 滋
1.はじめに
皆さんの中には、人間の音声を聞き分ける装置、つまり音声認識装置がすでに出回っていることをご存じの方も多いでしょう。そしてまた、これらの装置が、人間の音声聞き取り能力におよそ及ばないとお感じの方も多いことでしょう。人間と機械の円滑なコミュニケーションによって支えられる高度情報社会を実現するためには、これらの音声認識装置も、現在のものよりも遥かに優れたも、言い替えれば、人間の能力にもっと近付いたものになることが望まれているのです。
ATR視聴覚機構研究所では、人間の能力に近い音声認識装置の実現に貢献すべく、音声認識に関する基礎研究を進めています。この記事は、こうした基礎研究の一部を紹介するものです。ここでご紹介する研究では、音声スペクトログラムリーディングと呼ばれる手法に関する人間の能力のモデル化に焦点が合わせられています。この研究は、今日の音声認識研究に広く取り入れられている確率モデル等を用いた研究とは異なるアプローチから進めているものです。
以下では、2章において音声スペクトログラムリーディングとは何かを説明し、3章から5章において筆者らが現在進めている研究の概要を紹介します。
2.音声スペクトログラムリーディング
図1は、/omoshiroi/という単語音声の音声スペクトログラムの例を示しています。音声スペクトログラムは、横軸を時間軸、縦軸を周波数軸とした平面上に、各時間一周波数におけるエネルギーの強さを濃淡によって表現した音声の視覚的表現法の1つです。これは、俗に声紋と呼ばれることがあります。
この音声スペクトログラムを目で見ることによって発声内容を読み取る手法が、音声スペクトログラムリーディングです。音声スペクトログラムリーディングは、音声スペクトログラム上の黒く濃い帯状の部分で表される音響特徴や、日本語固有の言語的特徴等、音声に関する種々な性質を用いて行われます。読者の皆さんも、訓練次第で、非常に正確に音声を読み取ることが出来るようになります。この訓練は、学校で外国語を学ぶようなものですが、訓練によってそうした読み取り能力を身に付けることができる人間の能力は驚くべきものです。
さて、音声認識装置の究極のモデルは人間の音声聞き取り能力にあるといってよいでしょう。この点からすると、筆者らの研究の関心も耳による音声聞き取り能力に向けられるべきです。実際、筆者らの研究所でも、人間の音声聞き取り能力の解明を目指した様々な研究が進められています。それでは、何故、耳とは直接関係の無い音声スペクトログラムリーディングの研究が行われているのでしょうか。それは、音声スペクトログラムリーディングの方が、音声聞き取りに比べ、そこで行われている人間の判断の様子を分析するのに遥かに適しているからです。
音声スペクトログラムリーディングのこうした特長をもう少し詳しく見てみましょう。皆さんは、「面白い話ですね」と言われた時、どのように音が分析されたのか、どうして/o/のつぎに/m/が聞こえるのかといったことを意識できるでしょうか。私達が音声を聞き取る時、耳や頭で行われていることを意識することは殆ど不可能です。一方、音声スペクトログラムリーディングでは、そこで行われる判断の大部分は意識的に行われます。これは、先にも述べたように、音声スペクトログラムリーディングが、外国語の勉強に似た訓練に基づいて行われるからです。ここでは、「ここがこうだから音韻の候補として""」といった具合いに、ちょうど文法に則って単語を決めるように、音の読み取りが進められます。意識されている判断内容は、容易に表現することができます。そして、表現された判断内容は、音声認識の強力なモデルとして利用されるわけです。
人間の音声聞き取りが最高のモデルだとすれば、音声スペクトログラムリーディングは、音声認識のモデルとしては確かに次善あるいはそれ以下のものです。しかし、音の入口が耳から目に変わったとはいえ、音声スペクトログラムリーディングにおける判断の進め方には、音声聞き取りと共通の或いは似通った部分も期待されます。この判断の様子を比較的簡単に把握できる音声スペクトログラムリーディングの研究は、次善の策とはいいながら、また極めて強力なアプローチでもあることが理解いただけたものと思います。
3.音声スペクトログラムリーディング能力の分布
それではいよいよ、筆者らが取り組んでいる研究についてご紹介していきます。音声スペクトログラムリーディングを音声認識手法のモデルと考えるためには、まず、優れた音声スペクトログラムリーディング能力の分析をする必要があります。ところが、これまで、日本語に関する本格的な音声スペクトログラムリーディングの研究は必ずしも十分には行われていませんでした。そこで、筆者らは、多数の仲間と共に、音声スペクトログラムリーディングの訓練を、1年以上に渡って積み重ねてきました。
さて、こうした訓練の成果はどうだったでしょうか。/o/、/mo/、/shi/といった1音毎の読み取り能力や、/omoshi/という音を/o/や/mo/、/shi/のように区分化する能力等、音声スペクトログラムリーディングにおける最も基本的な能力を分析した実験結果によれば、非常に優れた音声スペクトログラムリーディング能力が獲得されていることが明らかになりました[1,2]。
4.試行錯誤的な読み取り能力のモデル化
筆者らは、以上の音声スペクトログラムリーディング能力の分析を基に、そのモデル化の試みも行っています。このモデル化で大事なことは、音声スペクトログラムリーディングにおける試行錯誤的な判断の進め方をモデルに反映することにあります。
それでは、試行錯誤的な判断とはどのようなものでしょうか。音声スペクトログラムの濃淡が全く同じであっても、音響特徴であると考えるべき時とそうでない時とがあります。このような判断では、注目している点の付近の状況に広く目を向け、「もしこれが/o/の音響特徴であるとすれば、""」といった具合いに、考え得る様々な場合を想定したつじつま合わせをする必要が生じます。試行錯誤的な判断とは、このように迷いながらあらゆる可能性を確かめ、最終的に正しい答えにたどり着こうとする判断のことです。読者の皆さんも、音声スペクトログラムの曖昧な濃淡模様を見ていると、こうした試行錯誤が実に自然なものに感じられるものと思います。
このような試行錯誤的な判断の進み具合いを実現するため、筆者らは、音声スペクトログラムリーディングのモデルの構成として図2に示すものを採用しました。図中、音響特徴抽出部は曖昧な濃淡図である音声スペクトログラムから黒い帯状の音響特徴を抽出する過程を、認識部は抽出された音響特徴を用いて音韻や単語等の認識を行う過程を、更に監督部はこの2つの過程の橋渡しを行う部分を表わしています。3番目の監督部は、これまでの大部分の音声認識システムには見られなかったものであり、人間の試行錯誤的な判断を模倣するうえで重要な役割を果たします。つまり、監督部は、考え得る音韻や音響特徴の仮説を考慮しながら、認識部の結果に基づいた音響特徴抽出のやり直しや、新たな音響特徴を用いた音韻の認識等を繰り返し行うわけです。
図2のモデルを具体的なアルゴリズムとして動作させる試みとして、筆者らは音響特徴の抽出と音韻の認識とを試行錯誤的に実行する手法を試みています[3]。この手法は、離散的緩和法と呼ばれるものの一つです。
図3は、この試行錯誤的手法から得られた音声のピッチ周波数の1例を示しています。「あーいーうー」のような声を出す時に喉に触ってみると、喉が震えることにお気付きでしょう。この震えの回数がピッチ周波数と呼ばれる音響特徴であり、声の高さに対応しています。図3(a)の音声波形では、/i/と/o/の部分に見られる尖った波形の繰り返しの回数が、ほぼピッチ周波数に対応しています。図3(b)はケプストラム分析と呼ばれる手法によって得られたピッチ周波数の軌跡で、これはまだ試行錯誤的処理に入る前のものです。喉が震えていないはず/k/の部分にもピッチ周波数が求められ、また、/o/の区間では3箇所にピッチ周波数の不連続点がみられます。もしこの不連続な結果が正しいものだとすれば、図3(a)の音声を聞いた時、「ブチッ」という音が聞こえるはずです。しかし、実際には、この音は極めてきれいな声です。図3(b)の分析結果がおかしいのです。図3(c)は、試行錯誤的な処理を数回繰り返した場合の結果を示しています。ここに示されたピッチ周波数の軌跡は、/i/と/o/の区間のみ滑らかに現れています。この結果は、図3(b)の結果より明らかに正確なものとなっています。
5.視覚的音響特徴ラベル
音声スペクトログラムから音響特徴が正確に得られたものとします。この音響特徴を用いて、どのように音韻や単語の読み取りが進められるのでしょうか。これは、図2中の認識部に焦点を合わせた興味深い研究課題です。筆者らは、この研究を効率的に進めるため、視覚的音響特徴ラベルを導入しました[4]。図4は、音声スペクトログラム上に記された視覚的音響特徴ラベルの例を示しています。視覚的音響特徴ラベルは、図が示すような多角形であり、音声スペクトログラム上の黒く濃い部分を取り囲むことによって正確に音響特徴を記述しています。
視覚的音響特徴ラベルの導入は、音声スペクトログラムリーディングの過程を部分的に研究することを可能にするわけですから、様々な実験の枠組みを新しく考えることができます。実際、筆者らは、視覚的音響特徴ラベルを用いることによって、音韻の連なりの種類が音響特徴の性質に及ぼす影響の分析を行ってきました[5]。実験はまだ多くの検討を必要としますが、影響の解明に必要な手がかりが少しづつ得られています。
6.むすび
以上、音声スペクトログラムリーディングとそのモデル化をめざして当研究所で進めている音声認識研究の一部を紹介しました。人間の試行錯誤的な判断の進め方が、これらの研究で重要な役割を果たしていることをご理解いただけたものと思います。
今日盛んに研究されている確率モデルに基づいた音声認識手法は、音響特徴の統計的な変動を吸収する点で極めて強力なものです。しかし、学習や適応の問題を考えますと、それらの手法も決して万能ではありません。筆者らは、ここで紹介した人間の能力のモデル化の研究が、確率モデルに基づく研究手法と相補いながら、将来の高度な音声認識手法の実現に貢献するものと考えています。
参考文献


