| 《解 説》 ニューラルネットワークとその音声認識への応用: 神経細胞(ニューロン)は、本体と本体から樹状に突出した樹状突起、1本の長い繊維組織からなる軸索から構成されています。軸索の先端はシナプスと呼ばれ、ここで他の神経細胞に結合します。シナプス結合を通して樹状突起に入力された他の神経細胞からの刺激(信号)は、刺激の重み付け等単純な処理の後、軸索を経由して次の神経細胞に伝達されます。人間の脳では、このような神経細胞が約100億個あり、これらがたがいに複雑に結合しあいネットワークを形成しています。これをニューラルネットワーク(神経回路網)といいます。このネットワークは学習等によってさらに複雑に成長しますが、使われないものは退化する等柔軟性を持っています。ニューラルネットワークの持つ情報処理機能は、ネットワークの形態や複雑な結合の仕方にあると考えられています。ネットワーク上では必要な機能を記憶した神経細胞だけが機能し、不必要な神経細胞は抑制して処理するため処理速度が速くなります。このシステムの動きを解明して、工学的に応用することがニューラルネットワークの研究の狙いです。このような機能をコンピュータ上でモデル化したものに、音声認識に用いられたニューラルネットワークがあります。ここでは、入力層から出力層までの4つの層の間にネットワークを張り、入力した音声信号の特徴に対して刺激を受ける素子が機能すると、この素子と重み付け(結合の度合いの強さ)をした次の層の素子に音声信号の特徴を強調した信号を伝達し、さらに次の層に伝達して特徴抽出を行うという方法で音声信号の認識を行っています。 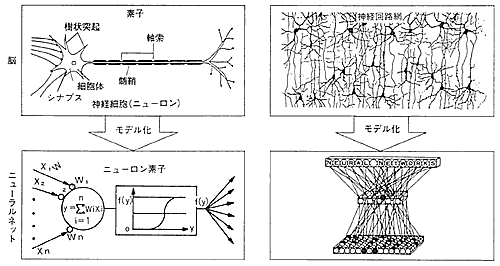 |