1. Introduction
Smooth communication in various daily situations is based on seeing
faces and hearing voices. In our department, we are carrying out research
on human communicative behavior utilizing psychological and engineering
approaches. In this article, I would like to introduce recent research
activities investigating human processing of the information received
from other people's faces and voices, and characteristics of perception/cognition
using that information.
2. “Stillness” and “dynamics” on faces
By paying even a little attention to faces and voices, you would easily
notice that our faces are always moving and also our voices are always
changing. However, the face itself has particular characteristics, whereby
even a single still photograph can deliver a variety of information
such as “is this person male or female?”, “how old is
this person?”, “do I know this person?” and “if
so, who is it?” etc. I can tell as a human vision researcher that
this system of human face perception is quite unique, since the system
can discriminate the pattern immediately only from slight differences
in basically the same static pattern of “two eyes at the top, then
below the eyes are a nose and a mouth.” Therefore, it may be no
exaggeration to say that the research field of faces has witnessed dramatic
development, specializing in information derived from static images.
In the past, these functions of human processing had been investigated
mainly with respect to “identification of the person,” “facial
expressions,” and “attributes such as age” using static
2D or 3D facial patterns. In contrast, our project is focused on the
human perception of facial “movement.”
As mentioned above, there is a broad range of information that can
be encoded from a single picture. However, there also exist cases where
dynamic information is necessary to facilitate such human functions
of processing, or it is necessary since static information cannot cover
an entire processing. For example, movement may be necessary to understand
“what is being said,” “changes of expression,” and
“change of attention direction by eye-gaze.” By focusing on
dynamic facial information, research progressed into the issue of matching
facial movement with our “voice,” another important source
of information received from faces.
3. Face and voice
“Hearing the speech contents” is one topic heavily focused
on in the research field of voice perception. “The McGurk effect”
clearly shows that seeing lip movement can affect voice perception [1].
For example, something magical happens in looking at a face saying /ga/
while hearing a voice saying /ba/ at the same time: it produces the
perception of a sound that is almost /da/. What we can understand from
this kind of illusion is that we perceive things not based on what we
see and what we hear individually but by integrating that information
multi-modally.
However, the human ability to process the integration of faces and
voices is not limited to hearing speech contents. Our group is studying
speaker identification from faces and voices. As mentioned before, historically
research has focused thus far on static properties of person identification;
however, recent research reveals that we can identify familiar people
by facial movement information. For instance, so-called biological motion
(point-light motion on the surface of the face), or a degraded monochrome
movie can be useful for identifying a person.
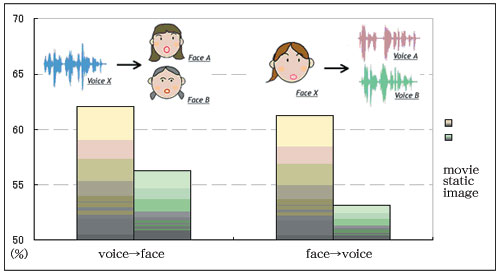
Additionally, in our own series of studies, we have shown facial
movies taken from unknown people followed by presenting unknown voices
to our participants to determine if they could judge whether the speakers
are the same person or not [3]. The most interesting finding from this
study is that the information coded uni-modally, a face or a voice,
can be matched by the other modality of information, even though there
is a delay in the timing of presentation. Moreover, information useful
for person identification is involved in both “faces and voices,”
and this information can be shared multi-modally. From the experimental
results, we concluded that the possible case of information matching
between two modalities is inherently dynamical and not available from
a static image (Fig. 1).