|

|
AKAHANE-YAMADA
Reiko Department of Multilingual Learning Human Information Science Laboratories |
|
|
Introduction
In order to acquire the ability to communicate aurally in a foreign language, gaining knowledge about vocabulary and grammar is not enough. One has to learn how to perceive and produce speech as well. When you perceive speech, for example, “It is a cloudy day, isn't it?” you have to decode the acoustic signal which originally forms the sequence of phonemes, /itizaklaudideiizntit/, and identify words based on acoustic-phonetic and acoustic-prosodic knowledge. When you produce this sentence, a different type of processing is required. You have to pronounce segments in a proper manner. Without these perception and production skills, you cannot understand other people's speech or you cannot produce speech that is comprehensible for listeners. Thus, there is no doubt that the basic knowledge about mechanisms of human speech perception, production and acquisition are necessary in order to develop an effective CALL (Computer Assisted Language Learning) system. In more detail, speech is processed in the brain at multiple processing levels, such as phoneme processing, vocabulary processing, prosodic processing, syntactic processing, etc. In our department, we focus on phoneme, prosody and vocabulary, and hypothesize that these are basic speech modules. We are examining the relationship among the modules as well as the nature of acquiring each module. We are also trying to develop a CALL system based on results of these investigations. In this approach, we utilize an interesting method, which is to examine various hypotheses by means of training experiments. For example, in order to examine the hypothesis, “learning in speech perception transfers to speech production ability because there is a link between speech perception and production,” we conduct a perception training study and look at the improvement in pronunciation ability from pretest to post-test. (In fact, we conducted a study in which native speakers of Japanese were trained to perceive English /r/ and /l/, and found that trainees' pronunciation ability of /r/ and /l/ improved by the perception-only training [1]. ) In this method, studies on mechanisms of foreign language learning and the development of effective training tools are just two sides of the same coin: A new finding derived from training experiments benefits the training system, and a better training system facilitates training experiments. Two studies based on this method are introduced below. Vocabulary learning |
||
 |
||
|
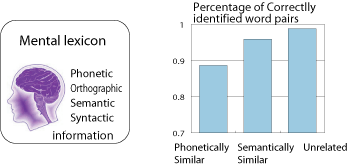
Fig. 1 .
|
Left panel shows the information stored in the mental
lexicon. Right panel shows the confusion in word pairs that are phonetically
similar and word pairs that are semantically similar (Modified from [2]).
|
|
|
Effect of contexts in the sentences
One may say that phoneme perception ability is not essential in listening
to speech, because one can judge each word or phoneme by using context.
A series of experiments were conducted to examine the effects of context
when native speakers of Japanese listen to English speech.
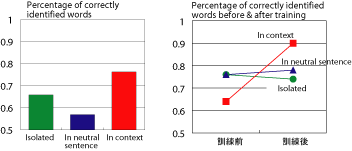
We have compared the accuracies of word identification in three conditions: 1) words presented in isolation (Ex. “flight”); 2) words presented in semantically neutral carrier sentences (Ex. “How would you say flight in your dialect?”); and 3) words presented in semantically meaningful carrier sentences (Ex. “It is a long flight to North America”). Results demonstrated that Japanese listeners identify words in neutral carrier sentences least accurately, and words in semantically meaningful carrier sentences most accurately (Figure 2, left panel). This result suggests that perception of second language speech is inhibited by acoustical context, but is facilitated by semantic context. Furthermore, we have found that identification training of words presented in semantically meaningful sentences improved trainees' identification ability only for words presented in semantically meaningful sentences, but identification ability for words in isolation or words in neutral carrier sentences did not improve (Figure 2, right panel [4]). Even though trainees have been exposed to speech thousands of times during training, what they have learned was to use the strategy to pay attention to semantic context (i.e., top-down processing) but not to the acoustical signal (i.e., bottom-up processing). These findings suggest the importance of bottom-up perception training in which learners cannot use semantic information in order to develop a robust perception ability.
|
|
|
|
Remarks References
[1] Akahane-Yamada, R., Tohkura, Y., Bradlow, A.R., & Pisoni, D.B. (1996). Does training in speech perception modify speech production? Proc. ICSLP '96, 606-609. [2] Takada T., Komaki, R. & Akahane-Yamada, R. (2004). Confusion in vocabulary in second language: Phenetic association and semantic association. Proc. 2004 Spring Meeting of ASJ, 431-432. (in Japanese) [3] Komaki, R. & Akahane-Yamada, R. (2004). Japanese speakers' confusion of phonemically contrasting English words: A link between phoneme perception and lexical processing. Proc. 18th ICA 2004, IV, 3303-3310. [4] Ikuma, Y., & Akahane-Yamada, R. (2004). An empirical study on the effects of acoustic and semantic contexts on perceptual learning of L2 phonemes. Annual Review of English Language Education in Japan, vol. 15, 101-108. |